‘LLM 모델’ 을 비교해서 최고의 모델은 무엇일까요? ‘클로드3 vs GPT-4 vs 제미나이 울트라’의 성능, 비용 등을 비교하여 어떤 모델이 가장 우수한지 알려드릴건데요. 최근에 나온 클로드3가 어째서 최강의 LLM 모델로 불리고 있는지도 알려드리도록 하겠습니다

목차
클로드3 vs GPT-4 vs 제미나이 울트라: 최강 LLM의 탄생 🏆
대형 언어 모델(LLM) 시장에서 최근 가장 주목받는 3대 강자는 단연 앤트로픽의 클로드3, 오픈AI의 GPT-4, 구글의 제미나이 울트라입니다.
이들 최첨단 대형 언어 모델(LLM)은 다양한 벤치마크 테스트에서 실력을 과시하며 최강자 타이틀을 두고 치열한 경쟁을 벌이고 있습니다.
이들 모델은 각기 강력한 성능을 자랑하는 최상위 모델들인데 과연 그렇다면 누가 진정한 챔피언에 오를 수 있을까요?
1. CoT(Chain of Thought)와 shot 개념 이해하기
먼저 이들 모델의 성능을 평가할 때 자주 등장하는 ‘CoT’와 ‘shot’이라는 용어를 설명하겠습니다.
CoT는 ‘Chain of Thought’의 약자로, 언어 모델이 문제를 해결하는 과정에서 중간 사고 단계를 자연어로 표현하도록 유도하는 프롬프트 기법입니다.
이를 통해 모델의 추론 능력을 향상시킬 수 있습니다.
한편 ‘shot’은 ‘few-shot learning’과 연관이 있습니다.
적은 수의 예시만으로도 새로운 문제를 해결할 수 있도록 모델을 학습시키는 기법인데, 여기서는 간단히 ‘예시’ 또는 ‘기회’를 의미한다고 보시면 됩니다.
2. 벤치마크 점수로 본 격차
3개 모델의 실력을 가리는 가장 중요한 잣대는 바로 다양한 벤치마크 테스트의 결과입니다.
클로드3는 대학 학부 수준 지식, 대학원 수준 추론, 기본 수학 등 전 분야에서 GPT-4와 제미나이 울트라를 앞서는 점수를 기록했습니다.
특히 오퍼스 버전은 프롬프트 이해도에서 인간보다 뛰어난 모습을 보이기도 했죠.
이미지 처리 벤치마크에서도 클로드3는 GPT-4와 제미나이 울트라에 버금가는 성능을 과시했습니다.
사진, 차트, 그래프, 다이어그램 등 다양한 유형의 시각 자료 분석 능력이 출중했던 것이죠.
하지만 GPT-4와 제미나이 울트라 역시 만만치 않은 성능을 가지고 있어요.
제미나이의 경우 100만 토큰의 컨텍스트 창을 자랑하며, GPT-4 역시 탄탄한 성능을 바탕으로 클로드3에 맞서고 있습니다.
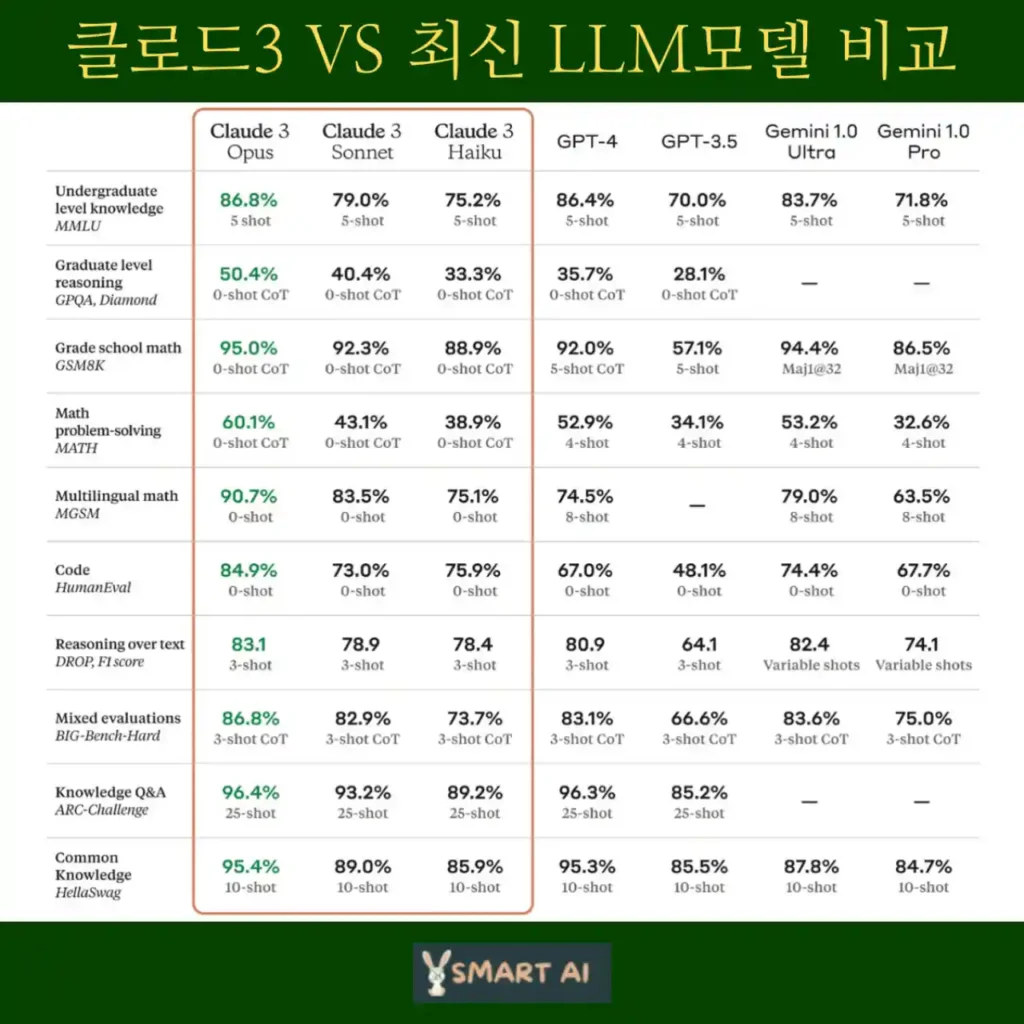
▶ 대학 학부 수준 지식 – MMLU: 5-shot CoT 세팅에서 Claude 3 Opus 86.8%, GPT-4 86.4%
▶ 대학원 수준 추론 – GPQA: 0-shot CoT에서 Claude 3 Opus 50.4%, GPT-4 35.7%
▶ 초등 수학 – GSM8K: 0-shot CoT에서 Claude 3 Opus 95%, Sonnet 92.3%, GPT-4 92%
▶ 수학 문제 해결 – MATH: 0-shot CoT Claude 3 Opus 60.1%, 4-shot GPT-4 52.9%
▶ 다국어 수학 – MG58 : 0-shot Claude 3 Opus 90.7%, 8-shot GPT-4 74.5%
▶ 코딩 – HumanEval : 0-shot Claude 3 Opus 84.9%, Sonnet 73%, Haiku 75.9%, GPT-4 67%
▶ 텍스트 추론 – DROP : 3-shot에서 Claude 3, GPT-4 모두 80점대
▶ 종합 평가 – BIG-Bench-Hard : 3-shot CoT에서 Claude 3 Opus 86.8%, GPT-4 83.1%
▶ 과학 지식 Q&A – ARC-Challenge : 25-shot에서 Claude 3 Opus 96.4%, GPT-4 96.3%
▶ 상식 추론 – HellaSwag : 10-shot에서 Claude 3 Opus 95.4%, Sonnet 89%, GPT-4 95.3%
벤치마크 성능 요약
3. 클로드3의 압도적 우위
전반적으로 봤을 때 Claude 3, 특히 최상위 버전인 Opus 모델이 여러 분야에 걸쳐 GPT-4와 제미나이 울트라를 앞서고 있음을 알 수 있습니다.
대학원 수준 추론, 수학 문제 해결, 다국어 처리, 코딩 등의 영역에서 Claude 3 Opus가 확실한 우위를 점하고 있습니다.
반면 GPT-4는 대학 학부 수준 지식, 상식 추론 등에서 강세를 보였습니다.
특히 Claude 3 Opus의 가장 큰 강점 중 하나는 장문 텍스트에 대한 놀라운 이해력과 기억력입니다.
최대 20만 토큰 길이의 거대한 컨텍스트 창을 지원하며, 일부 유료 고객에게는 무려 100만 토큰을 초과하는 창까지 제공한다고 하죠.
LLM 모델 상세 비교
클로드 3, gpt-4, 제미나이 울트라 이상 3개의 모델의 장단점, 코딩성능, 비용을 상세하게 비교해 보겠습니다.
모델별 장단점
- 클로드 3
- 강점: OCR(광학 문자 인식), 복잡한 쿼리에 대한 미묘한 이해, 벤치마크 성능 향상, 이미지 속 번호판 번호 등 정확하게 시각 인식, 한 번에 최대 20개 이미지 분석
- 한계: 낮은 해상도 이미지 분석 부족, 이미지 속 기상 조건 등 미묘한 디테일 감지 부족, 2023년 8월 이전의 데이터로 학습, 최신 웹 검색 불가
- 앤트로픽의 주장: 코딩 및 OCR에서 챗GPT 및 제미나이보다 성능 뛰어남(벤치마크)
- GPT-4
- 강점: 광범위한 지식 기반의 강력한 대화 기능, 쓰기, 요약, 질문 답변을 포함한 광범위한 텍스트 기반 응용 프로그램의 탁월한 성능, 사용자 친화적
- 한계: 특정 기술 벤치마크 뒤처짐, 컨텍스트 창이 클로드보다 적음
- 제미나이 1.0 울트라
- 강점: 비전 작업과 일반 AI 기능에서 강력한 성능
- 한계: OCR 영역에서 경쟁우위 낮아짐, 클로드3과 경쟁

코딩 성능 비교
- 클로드 3: 복잡한 쿼리, OCR 및 이미지 추론과 같은 전문 작업을 처리하는 데 있어 상당한 발전. Haiku, Sonnet, Opus 계층화로 사용자는 간단한 쿼리부터 복잡한 분석까지 특정 요구 사항에 가장 적합한 모델 선택 가능.
- GPT-4: 상세한 토론에 참여하고, 광범위한 질문에 답하고, 인간과 같은 텍스트를 생성할 수 있는 대화형 AI를 만드는 데 탁월.
- 제미나이 1.0 울트라: 텍스트와 시각적 정보 혼합 처리의 경쟁 우위. Claude 3과 시각 정보 처리에서 경쟁하며, 더 깊은 상황별 이해와 정확성 개선 예정.
비용 비교
- 클로드 3 (각각 백만 입력 토큰당, 백만 출력 토큰당 가격)
- Opus: $15 / $75
- Sonnet: $3 / $15
- Haiku: $0.25 / $1.25
- GPT-4
- GPT-4 터보: $10 / $30
- GPT-4: $30 / $60




핑백: GPT-4o vs GPT-4 비교 및 사용방법